Re:Server - 03. 서버보다 MCP 이야기가 더 많은 서버 재설치 마지막 이야기
홈서버 재구축하기 3부작 중 마지막입니다. 그런데 홈서버 내용보다는 MCP에 대한 내용이 더 많네요.


서비스기획자 용진입니다. 오랫만이네요. 저도 이렇게 오래 걸리게될 줄은 몰랐습니다. 공사로 아주 일이 쏟아지고 있는 나날입니다. 그래서 이번 글로 서버를 재설치하는 내용을 마무리지어보려고 합니다.
일체유심조를 깨닫다
일체유심조(一切唯心造)라는 말이 있습니다. [화엄경]이라는 불교 경전에서 나오는 말인데, "모든 것은 오직 마음이 지어낸다"라는 뜻입니다. 원효 대사가 당나라 유학가던 길에 해골물을 먹고 '이것이 일체유심조구만?'을 깨닫고 돌아온 이야기가 유명하죠. 서버 만들다가 이게 무슨 이야기인가 하면 제가 그랬거든요(...)
근데 서버는 어떻게 다시 설정했나요?
믿었던 ChatGPT의 삽질은 어처구니없게도 Claude로 한 번에 해결되었습니다(...) 저는 정말 저 질문 하나만을 던졌는데 한번에 성공할 수 있었습니다. 물론 저 친구 입장에서는 한번 질문한 것은 아닐겁니다. 제가 Claude와 함께 사용한 건 sequential-thinking 라는 이름의 MCPModel Context Protocol 입니다.
What's MCP?
요즘 Claude나 CursorAI를 사용하고 있는 사람이라면 MCP를 모를 수 없을 정도로 MCP는 하나의 표준이 되었습니다. 그런데 Model Context Protocol, MCP가 대체 무엇이길래 그럴까요?
Model Context Protocol라는 단어를 하나하나 뜯어보죠. Model은 LLMLarge Language Models을 뜻합니다. Context는 사전적으로는 '상황, 맥락, 문맥 상의 의미'를 뜻하지만 IT쪽에서는 '상황에 대한 정보'로 해석하는 것이 더 적절하다고 봅니다. 마지막으로 Protocol도 IT 쪽 의미로 '통신 규칙' 정도로 이해하시면 됩니다. 지금까지 따로 해석한 것들을 모아보면 Model Context Protocol는 '대규모 언어 모델의 상황 정보에 대한 통신 규칙'이라고 해석할 수 있겠네요.
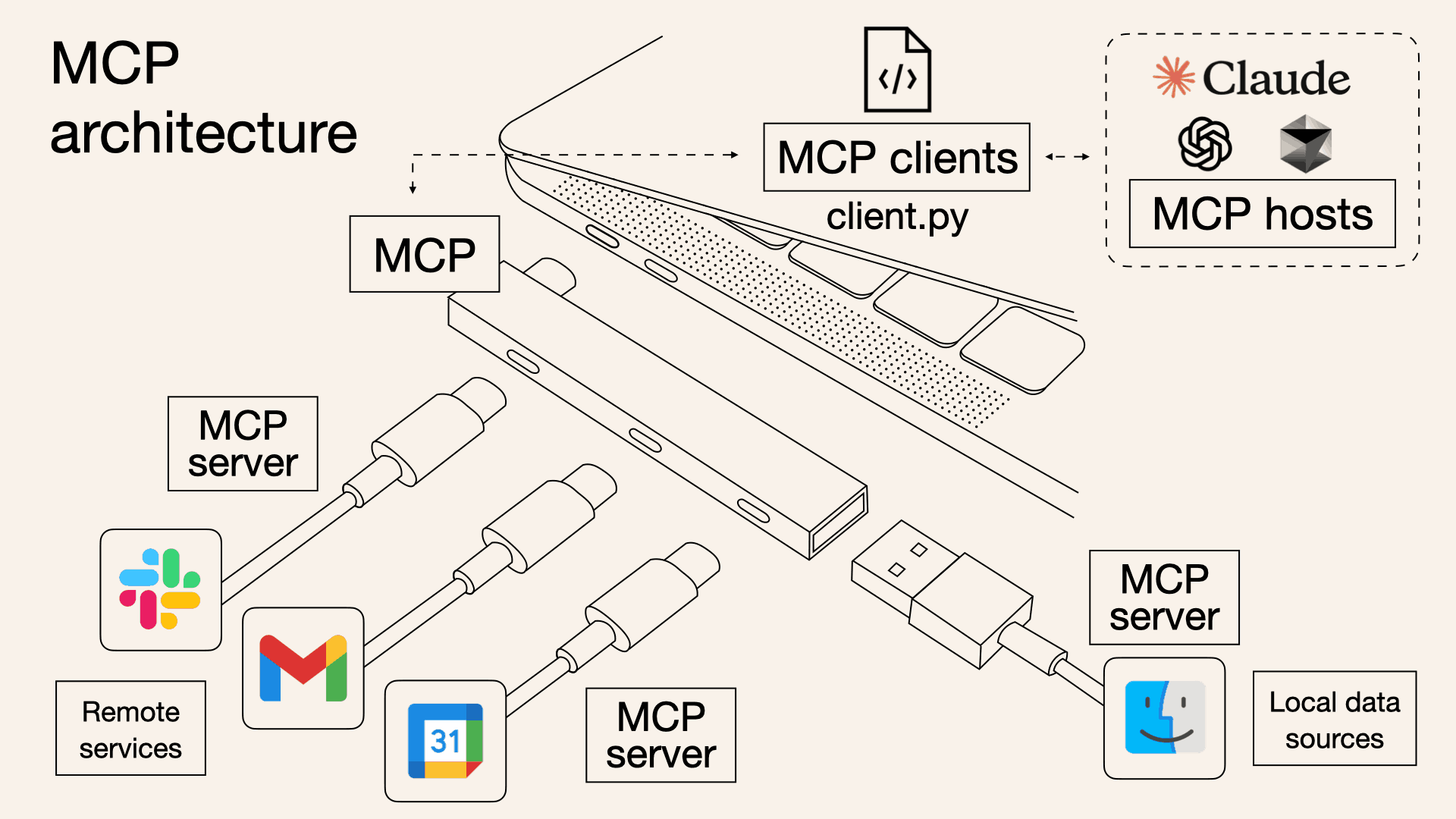
Why MCP?
ChatGPT나 Claude, Gemini, LLama, Grok과 같은 LLM은 기본적으로 트랜스포머Transformer라는 딥러닝 아키텍처를 기반으로 하고 있습니다. 너무 어려운 이야기는 다음에 하도록 하고(= 다음 포스팅거리다) 중요한 것은 "우리에게 내놓는 모델은 일정 기간까지의 데이터를 학습한 결과물이다."라는 것이죠. 즉, 우리에게 내놓는 대답은 일정 시점을 기준으로 이전의 데이터인 것입니다.
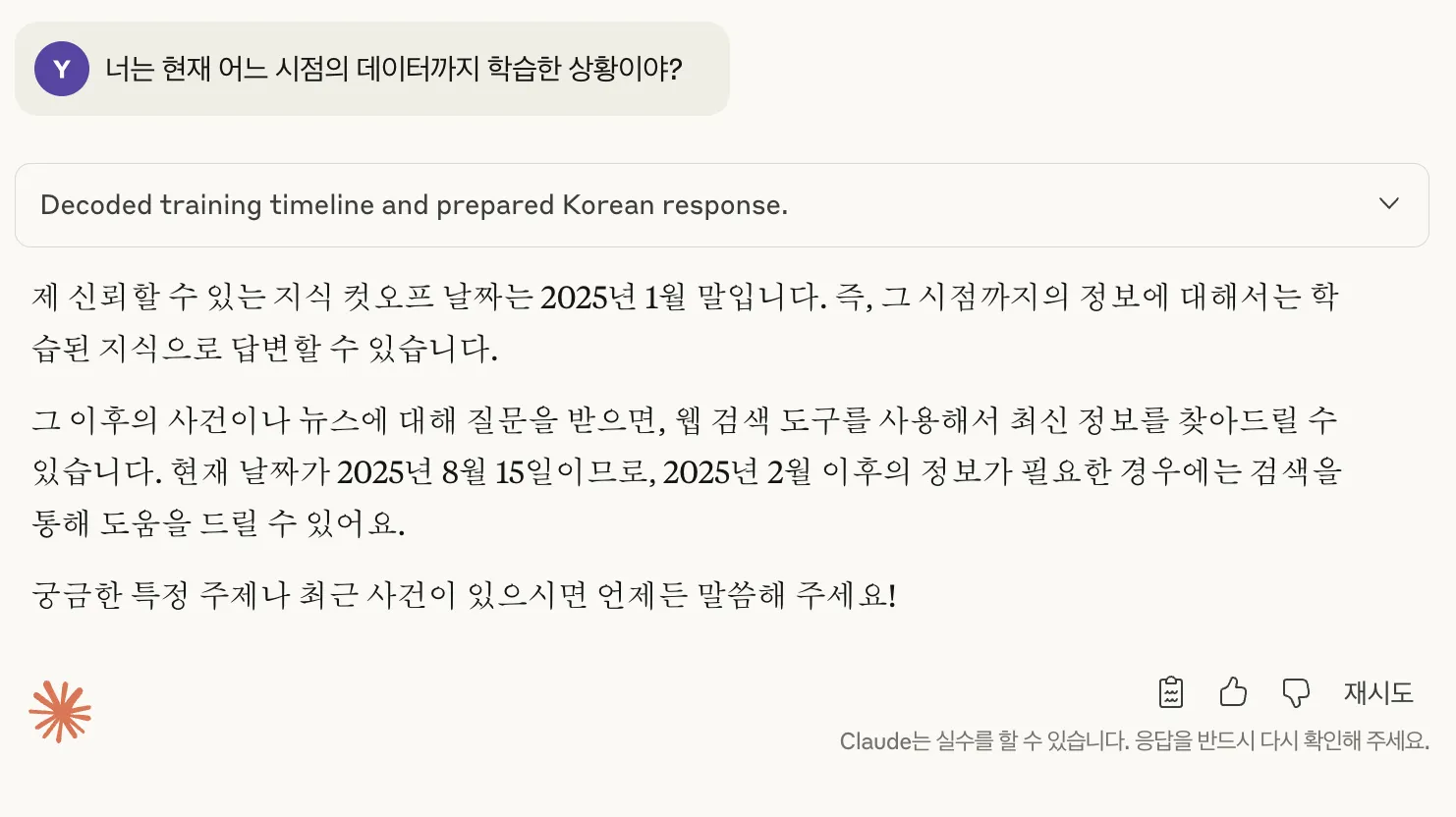
그렇다면 최신의 정보는 어떻게 줄 수 있을까요? 요즘 LLM 서비스를 제공하는 회사 대부분은 자체적인 웹 검색 기능을 제공하고 있지만, 웹 검색으로 해결하기 어려운 정보의 경우라면? 아니면 반대로 LLM을 통해서 다른 것을 제어하고 싶다면?
첫번째로는 APIApplication Programming Interface를 통한 방법이 있겠죠. 그렇지만 API는 각 모델별로 따로따로 만들어야합니다. 제가 요즘 주로 사용하는 Claude 모델을 사용하는 파이썬 코드는 다음과 같을겁니다.
import anthropic
client = anthropic.Anthropic(
api_key="sk-dkwowkdkd..."
)
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1000,
messages=[
{"role": "user", "content": "안녕!"}
]
)
print(message.content)이러한 방법을 각 모델별로 따로따로 만든다? 그리고 모델이 달라지면 그때그때 바꿔줘야한다? 이것은 Very 귀찮다. 그리고 이것은 프로그래밍에서만 사용할 수 있는 방법이죠. 개발을 할 줄 모르는 저희같은 사람들은 채팅창에 치기만 하면 되는 것을 원한단 말입니다. 하지만 MCP? Very 간단하다. 네 Claude 설정에 이것만 추가해라.
{
"mcpServers": {
"sequential-thinking": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-sequential-thinking"
]
}
}
}그렇습니다. MCP가 뜬 이유는 다른 게 아니라 "겁나 사용하기 편하다" 입니다. 모델별로 따로 만들 필요도 없습니다. 해당 규격만 맞춰 개발하면 Claude에 붙이든, CursorAI에 붙이든 저 코드를 똑같이 붙이면 됩니다. 어느 모델에든 사용 가능하도록 만든 규칙. 이것이 MCP인 것입니다.
그건 알겠고 MCP를 왜 씀?
유용하기 때문이죠.(정답) 다시 처음으로 돌아가서, 제가 유용하게 사용하는 sequential-thinking MCP를 살펴보도록 하죠. 요즘은 컨텍스트 엔지니어링Context Engineering이 뜨고 있지만, 보통 사람들은 ChatGPT나 Claude를 "내가 묻는 것에 대답해주는 도구" 정도로 사용하고 있습니다. 그렇기에 보통은 "이거 하려면 어떻게 해야해?" 정도의 질문만 던지죠.
간단한 문제라면 정답이 금방 나오겠지만 그렇지 않을 경우에는 엉뚱한 답을 받는 경우를 겪어보셨을 겁니다. 그 대답에 화를 내면서 추가적인 정보를 주면 "아, 제가 잘못 이해했네요. 그렇다면..." 하면서 제대로 된 답을 주면 좋겠지만 또 엉뚱한 말을 하는 경우도 있죠. 왜냐면 기본적으로 LLM은 학습한 내용을 바탕으로 '해당 상황에서 제일 나올 확률이 높은 단어들을 밷어내는 것'에 가깝거든요.
그렇기 때문에 질문할 때 상세하게 작성하도록 요구받았고, 그것이 발전하여 프롬프트 엔지니어링prompt Engineering 까지 온 것이죠. 실제로 Lovable이라던가 LLM 모델을 사용하여 추가적인 무언가를 하는 서비스는 이러한 프롬프팅으로 구성되어 있습니다.프롬프트 잘 짜는 것도 기술이다
하지만 아까도 말했다시피 90%의 보통 사용자들은 깊게 생각하지 않고 던집니다. 그러면 엉뚱한 답을 할 확률이 높아집니다. 그렇다면 엉뚱한 답을 하지 않게 하려면 어떻게 하면 될까요? 질문을 잘 던지면 됩니다. 하지만 보통은 안그렇다고 했죠? 그러면 그런 질문을 LLM이 스스로 잘 쪼개서 생각하고 생각하게 만들게 하면 되는 겁니다. 그게 바로 순차적 사고 sequential-thinking MCP 입니다.

즉, 이러한 MCP 를 사용하여 더 효율적으로 LLM을 사용할 수 있습니다. 더 나아가 LLM 외부의 것을 LLM이 컨트롤할 수 있게 하는 것도 가능하죠. Figma나 Blender가 이미 MCP를 지원하고 있죠. 이 글을 보시는 여러분들도 한번 사용해보시면 좋겠네요.
다시 서버 이야기로 돌아와서...
sequential-thinking MCP는 제 질문을 스스로 잘 쪼개서 분석하고 적절한 답을 주었습니다. 여기서 만들어준 docker-compose.yml 과 dynamic.yml은 Re:Server output에 정리해두겠습니다. Claude의 설명을 보면서 시키는대로 하는 중에 다음과 같은 내용을 보게 됩니다.
서브도메인에 별표Asterisk, 애스터리스크 를 달고 인증서를 받을 경우 와일드카드 인증서Wildcard SSL라고 부르며 해당 방식으로 인증서를 받을 경우 서브도메인마다 별도로 인증서를 받을 필요가 없어집니다. 그런데 전 이전에 해당 방식을 사용하지 않았습니다. 아니 정확히 말하면 사용하지 못한 것에 가깝습니다. 저는 Public Hostnames 탭에서 다음과 같이 설정했거든요.
yongjin.dev -> http://treafik:80
n8n.yongjin.dev -> http://n8n:3456
karakeep.yongjin.dev -> http://karakeep:3000
...어떠한 서비스를 추가하면 해당 서비스의 도메인을 만들고, 그 도메인에 다음과 같이 포트를 입력하는 방식이었습니다. 그리고 이번에 Claude가 알려준 방식을 보고난 뒤 제가 이전에 traefik을 사용하여 리버스 프록시를 구축했다 생각했던 것은 해골물이었다는 것을 깨달아버린 것입니다.
나는 리버스 프록시를 쓰고 있지 않았다
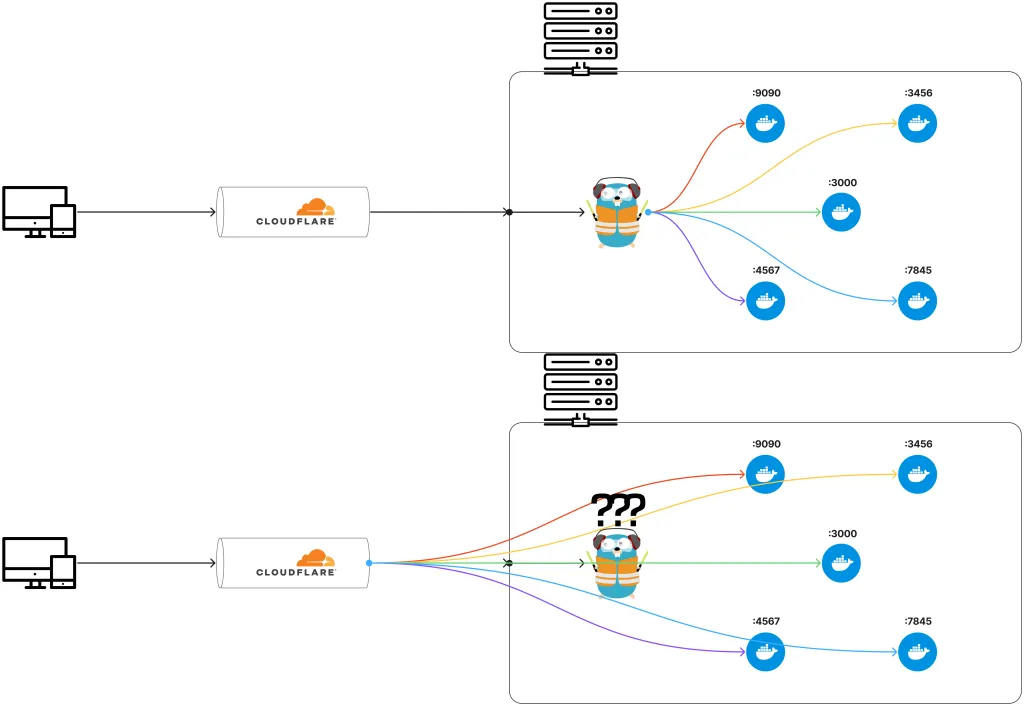
Figma로 간단하게 만들어보았습니다. 저는 이전에도 위와 같이 traefik이 분배를 해준다고 생각했지만 실제로는 아래와 같이 직결하고 있는 상황이었던 것입니다. 어째 ChatGPT에게 서비스 추가하는 법을 요청하면 계속 http://traefik:80을 알려줬었거든요. 하지만 전 저 방법으로 했을 때 연결된 적이 없어서 매일 ChatGPT에게 "제대로 된 방법을 알려달라."고 다그쳤습니다. 하지만 제대로 된 방법을 못쓰고 있던 것은 저였다는 이야기입니다.
결론: 지금은 잘 됩니다.
결론적으로 지금은 잘 돌아가고 있습니다. 지금은 Portainer에 Stack만 올려도 도메인도 알아서 만들어지고 있기에 굳이 추가적인 작업을 할 필요가 없죠. 그렇기 때문에 아주 즐거운 홈서버 생활을 즐기고 있습니다. 읽어주신 여러분들 모두 감사드리며 여러분도 홈서버에 한번 도전해보심이?



